fluentassertions-analysis
Fluent Assertions assessment using CodeScene
Instead of writing a single article, this is the first part of the assessment of Fluent Assertions. This assessment mainly focuses on the non-test code using the Code Health features of CodeScene. This within the scope of using the tool to identify refactoring targets for the short term (7.0) and medium term changes to Fluent Assertions. This inventory of the public issues of Fluent Assertions can be found in the change forecast. The CodeScene project & data itself is publicly visible. I’ll first describe some of the high level output after which I do some further analysis of the details and the applicablity of the reported findings. This is very interesting case to show that some technical debt is actually instrument in achieving specific results and can be deliberate for other maintainability reasons.
Hotspots
For a first analysis and also learning CodeScene I’m using the Hotspots Code Health as a starting point. A hotspot is basically a file that has seen a high amount of recent changes. The code health with conjunction of the hotspots results in Refactoring Targets. These are the elements of the code that change a lot and have a lower health score. The Code Health is an aggregated score based on violations and warnings of certain rules. For the full details see the documentation itself. But this is is a summary of the Code Health:
Code Health is an aggregated metric based on 25+ factors scanned from the source code.
It is composed of:
- Module level issues
- Function level issues
- Implementation level issues
Code Health Hotspots
The tool doesn’t provide a simple export button. But fortunately the dev tools provided the API endpoint that outputs
what is called biomarkers.csv which contains the Hotspot Code Health data. I would
be expecting a full list here. I believe the time dimension plays a role in the selection. But let’s start with working
what we have for now. It’s easy to see a pattern here, especially if we leave out the tests. 7 our of 12 files (58%) of
the refactoring targets are classes that end with Assertions.cs. And they take the top 6 of the list. Many of the
later mentiond files don’t even have a bad Code Health rating (> 8) so it’s not fully clear why they’re listed here.
Refactoring Targets
These are identified using an algorithm that not only takes into account the Code Health but also the change frequency but also other aspects such as change coupling and amount of devs making changes making it a potential coordination bottleneck.
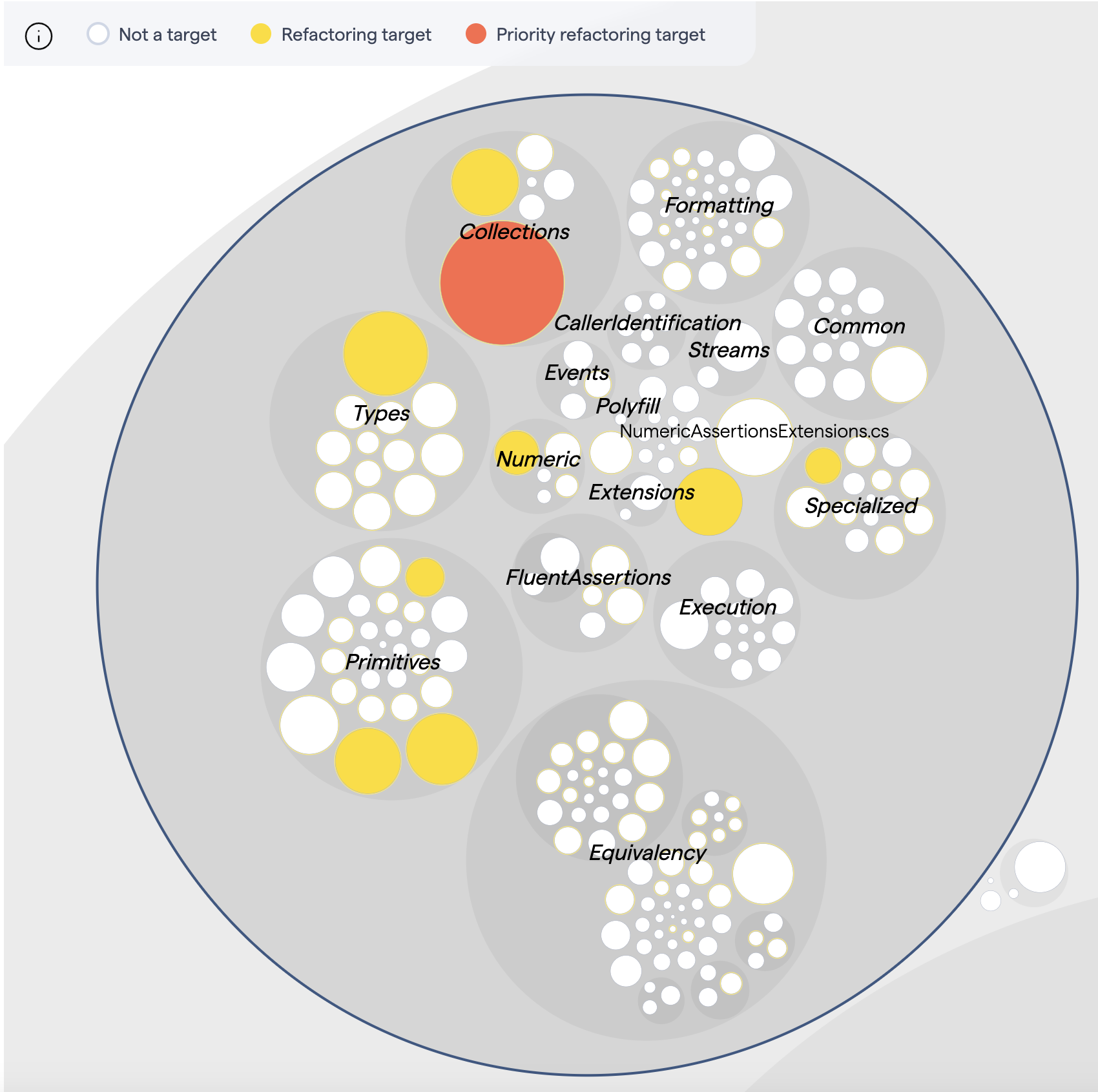
Priority Targets
- Collections/GenericCollectionAssertions.cs (5)
- CollectionSpecs.cs (5)
Targets
- Collections/GenericDictionaryAssertions.cs (7)
- Types/TypeAssertions.cs (5)
- AssertionExtensions.cs (8)
- Primitives/StringAssertions.cs (6)
- Primitives/DateTimeOffsetAssertions.cs (7)
TypeAssertions is an example that more than just the Code Health score determines (the priority of) a refactoring target.
Change Coupling
Change couping is a algorithm that identifies how often certain file pairs are changed together. This is grouped by commit, same developer within time period or same ticket id’s. In case of the latter provided those are available in the commit messages or a linked issue tracker. Change coupling can show patterns that might go unnoticed otherwise. It could surface duplication or otherwise concepts that deserve a dedicated abstraction.
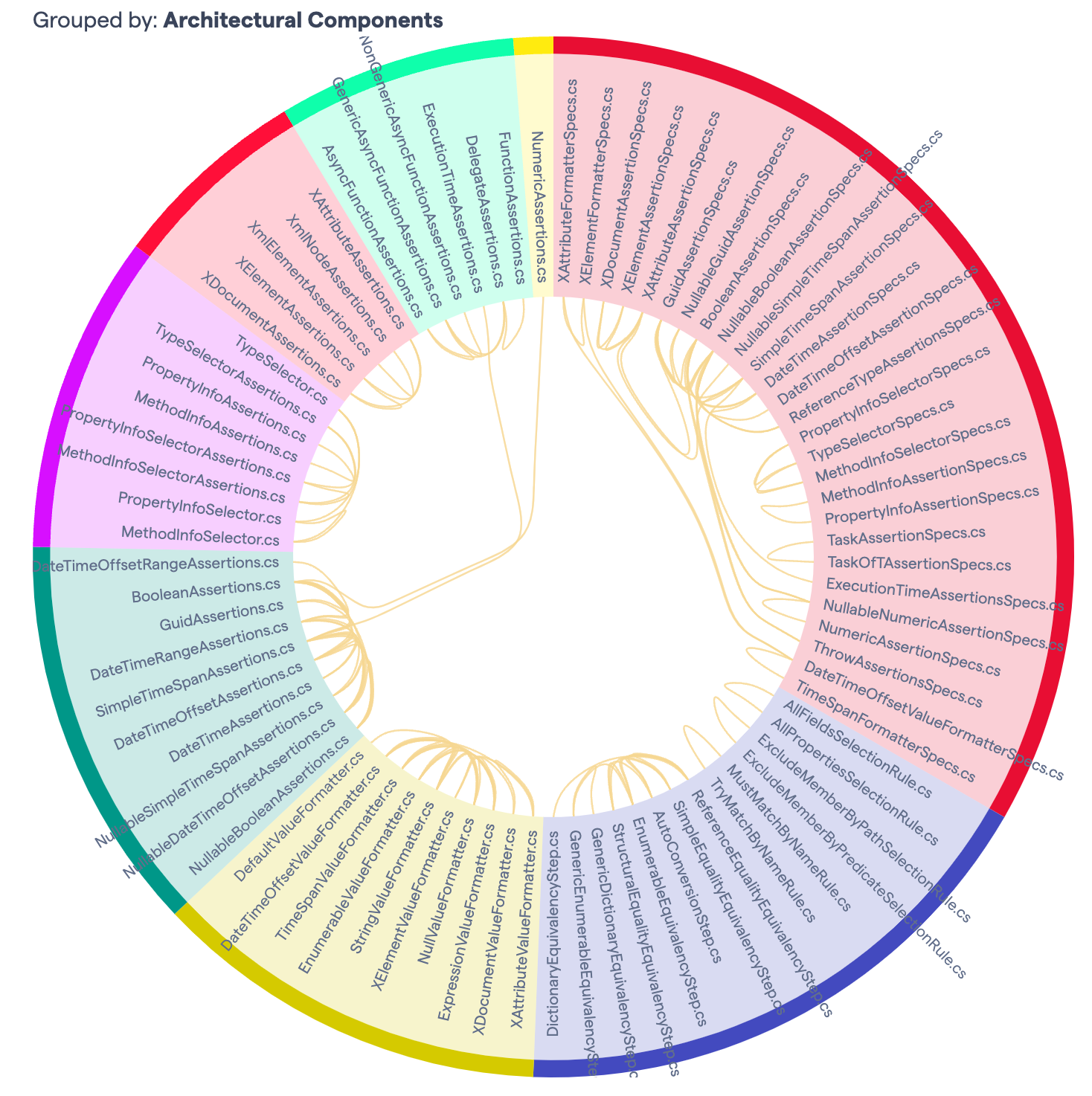
If we filter out the tests we see that most change coupling stays within namespace boundaries. What I’m really missing here is to quickly inspect the changes in the commits where this coupling occurred. This makes pattern understanding a rather cumbersome process. And I could really find a git log command to search the commits that contain this pair. But let’s just zoom in on cross boundary couples manually then.
By Commit
Specialized/ExecutionTimeAssertions.cs<->Primitives/SimpleTimeSpanAssertions.csNumeric/NumericAssertions.cs<->Primitives/BooleanAssertions.cs
Across Commits
TypeExtensions.cs<->Types/MethodInfoSelector.cs
Pattern(s)
It’s very cumbersome to find all the commits that contain the pairs and then look at the changes. But overall picture is that the change coupling is related to general improvements in certain idioms regarding input checks language support and messaging. In the latter there’s some duplication present but with variations so refactoring return on investment is rather minimal. Across commits coupling is the same. So there’s a lot of noise in this change coupling.
Crank up the coupling degree
If we crank up the minimum coupling degree to 75% the change coupling is limited to some in module files such as:
Formatting/ExpressionValueFormatter.cs<->Formatting/NullValueFormatter.csEquivalency/Selection/AllFieldsSelectionRule.cs<->Equivalency/Selection/AllPropertiesSelectionRule.cs
There are two patterns emerging here:
- Interface changes.
- Small duplicates behind these interface implementation. The X-Ray feature is a good tool to browse duplicates.
Analysis
Further analysis will zoom in only the Code Health. The patterns that emerged from the change coupling samples are
fairly small, benign and by now more stable parts of the code that haven’t realy changes a lot recently. None of these
types also really surface in the hotspots. The pattern in the Code Health Hotspot data is quite clear however, it’s
mostly Assertions classes that are identified as problematic. The name also clearly indicated these are a rather
fundamental part of the application.
The overall pattern in most of these classes is that they violate rules regarding (Potentially) Low Cohesion, Deep, Nested Complexity or Bumpty Road. The latter two I would categorize as complexity. Let’s look in more detail to the violations & warnings.
Violations
Cohesion
CodeScene measures cohesion using the LCOM4 metric (Lack of Cohesion Measure). With LCOM4, the functions inside a module are related if a) they access the same data members, or b) they call each other.
Now from the perspective of A) the Assertions are quite cohesive, most of them access the only piece of instance data,
the Subject. However, many of the methods indeed do not call each other unless it’s convencience overloads. There is
however a good reason for this, the Assertions classes are essentially what makes the API Fluent. Each static
Should extension method returns an instance of a type/context specific assertion class that provides all the possible
means to Assert that object. The amount of functions is thus determined by the amount of different assertion that can be
done on a specific type. The fact these classes are the essence of the library’s fluent api make change break and fixes
will huirt discoverability of the API. Fixing this cohesion problem for that reason hurts more than it solves.
Complexity / Bumps
This is a less common violation and it’s not influenced by a fundamental aspect of the design. It is a function level metric and the hotspots are thus also in specific functions. Given they’re both related to complexity there is overlap but not necessarily. Code with high complexity can still contain a single bump. The X-Ray feature is a very helpful feature in actually identifying function level hotspots. Let’s look at the X-Ray of the priority refactoring target Collections/GenericCollectionAssertions.cs. Here we see that those functions scoring high on complexity are actually not the biggest and most frequently changed functions in the class.
Warnings
Are as the name suggest considered less of a problem for the code health but can indicate maintainability issues. But not all warnings are created equal. Some might be very well explained by library purpose or deliberate design decisions.
Duplication - the biggest common denominator
There is a large degree of duplication visible in these hotspots. Sometimes involving about half of the functions for
instance for
TypeAssertions.
There is no quantification for the amount of duplication detected for the whole file. The
Internal Change Coupling
of the X-Ray does show the degree of similarity. I am used to assessing duplication in terms of percentages. CodeScene
chooses not to report such percentages and only duplicates and their degree of similarity. The fact that for each
assertion there is often a negated version of it is an important reason there are many duplicates. All assertions
functions are also simply structurally identical in that they check inputs, execution assertions, return fluent
interface results. Now for some the degree of similarity is higher than others. This implies that you although fairly
doable to reduce duplication of some but not all it would result in inconsistency in implementation. I assume that it’s
for that reason to deliberately remain consistent throughout the library’s assertions implementations and thus accept a
level of duplication.
Primitive obsession
A large part of the api exposes the means to provide reasons with potential formatting parameters. There are strings and
object arrays. For another part the library is built to assert values of primitives. So it should come as no surprise
for certain Assertions classes.
Conclusions
What started off as an analysis resulted in a certain necessity to describe CodeScene itself. It was also the first time I’ve been using it myself. So apart from drawing conclusions from it’s output in regards to the questions what candidates we can identify for refactoring I will spend a few words about (the applicability of) the tool itself.
Refactoring candidates
The Assertions parts of the codebase identified as problematic are also the parts which are very resistant to change.
Because addressing the violations for a large part implies introducing breaking changes to the essence of the library, a
Fluent API that needs discoverability. I don’t see any way out of that apart from redesigning the whole API or adding
complexity using facades to achieve better modularization. This renders a lot of the hotspots as a mere immutable fact.
They can basically be treated as false positives that should be filtered from the results. It’s mostly the
complexity dimension where improvements are still possible. And some debates can be had about the desirability of
certain clones although I believe those are jsutified for consistency reasons. Looking at the short term 7.0 priorities
this will provide more value on the medium term. For an open source project such improvements are nice for new devs to
contribute but by no means relevant to any near term changes.
So based on the data provided by CodeScene this is not bad news. The code that is more open to change is of quite good quality. This is confirmed by the average Code Health of 9. With some further tweaking & filtering it is probably possible surface some less urgent but still valuable improvements.
CodeScene
It was the first time I’ve been using CodeScene after I started reading the books of CodeScene’s founder, Adam Tornhill. In this assessment I have only been playing with the features regarding the Code Health parts of the tool. Purely based on the outcomes the debt is relatively well under control. It mostly showed that certain debt can be hard if not impossible to reduce due to API design decisions combined with a high public consumption of that public API. Leaving that aside the remaining debt identified is fairly limited. I’m inclided to say it mostly added value making explicit what should not be fixed. For the goals of identifying and fixing debt related to shorter term the value remaining was limited to some complexity & duplication. Metrics that are not unique to CodeScene in identifying. And that debt does not directly seem to affect the roadmap.
Which does not say it can’t provide value on the longer term to maintain quality. There are parts which I have not been using either because they’re not within the scope of this assessement or due to license limitations which could provide value. One thing within the license is the knowledge distribution which could be relevant in assessing possible documentation gaps or needed handovers. Another interesting element is the defect tracking which adds another dimension onto the hotspots. After all, those hotspots with the largest amount of fixes are most relevant candidates for refactoring. I definitely see a lot more value of applying CodeScene in larger scale commercial contexts. Features such as the delivery performance look very valuable in improving release frequency. It also knows how focus on it’s core strengths of temporal & team analysis by allowing for synergy with other static analysis tools such as SonarQube. This combination I believe can be highly valuable in maintaining quality to aid in high delivery performance.